

DeepSeek V4 chega com arquitetura MoE e janela de 1 milhão de tokens para revolucionar tarefas de agentes de IA de longa duração. Entenda como a nova arquitetura reduz custos de inferência e resolve falhas críticas em fluxos de trabalho complexos com chamadas de ferramentas.
📊 Resumo: Veja abaixo a análise completa e os impactos práticos para profissionais e empresas no Brasil.
Tempo de leitura: 3-5 minutos | Atualizado em 2026-04-24 00:00:00
🇧🇷 O Que Isso Significa para o Brasil?
Com o crescimento do ecossistema de IA no país e discussões sobre regulação (PL 2338/2023), avanços em inteligência artificial, machine learning e automação impactam diretamente profissionais, startups e empresas brasileiras. Fique atento a:
- 🎓 Capacitação profissional: Demanda por habilidades em IA cresce 3x ao ano no mercado brasileiro
- ⚖️ Marco Regulatório: Proposta de lei sobre IA pode afetar desenvolvimento e uso de ferramentas
- 🏢 Adoção empresarial: Setores como saúde, jurídico e financeiro lideram implementação de IA no Brasil
Análise Completa
DeepSeek lançou V4 hoje. Dois pontos de verificação MoE estão no Hub: DeepSeek-V4-Pro com parâmetros totais de 1,6T com 49B ativos e DeepSeek-V4-Flash com 284B total com 13B ativos. Ambos têm uma janela de contexto de token de 1 milhão. Os números de benchmark são competitivos, mas não SOTA. Não importa. A verdadeira inovação é como o DeepSeek v4 foi projetado para suporte eficiente a grandes comprimentos de contexto e, portanto, como um dos melhores candidatos para tarefas de agente.
Foco em cargas de trabalho de agente de longa duração. A execução de um modelo de fronteira aberta como agente hoje quebra de forma previsível. O modelo para. Você repreende. O rastreamento ultrapassa o orçamento de contexto, ou o cache KV preenche a GPU, ou as viagens de ida e volta de chamada de ferramenta são degradadas no meio de uma tarefa longa. A V4 foi criada para corrigir essas falhas conhecidase apontar o caminho a ser seguido pela comunidade.
Esta postagem cobre três coisas: o que a arquitetura faz de diferente para tornar barata a inferência de contexto longo, as decisões pós-treinamento específicas do agente que se somam a ela e algumas conclusões do artigo que ajudam a raciocinar sobre essas mudanças.
O problema do cache KV para agentes
Uma janela de contexto de 1 milhão é apenas capacidade, não desempenho. Se você pode usá-lo depende do custo de cada passe para frente nessa profundidade. Para um agente executando uma longa trajetória de uso de ferramenta (uma tarefa SWE-bench, uma sessão de navegação em várias etapas, uma sessão de terminal com centenas de comandos), cada resultado da ferramenta é anexado ao contexto e cada token subsequente paga o custo total de atenção em relação a tudo o que veio antes.
Dois números são importantes: FLOPs de inferência de token único e tamanho do cache KV. Ambos crescem com o comprimento da sequência. Com 1 milhão de tokens, o DeepSeek-V4-Pro requer 27% de FLOPs de inferência de token único em comparação com o DeepSeek-V3.2, por isso é executado mais rapidamente no mesmo hardware. Ele também usa 10% da memória cache KV. O V4-Flash reduz ainda mais esses números: 10% dos FLOPs e 7% do cache KV.
Se compararmos a memória cache KV com uma arquitetura estabelecida, como atenção de consulta agrupada com 8 cabeças, armazenada no formato bfloat16 usual, o DeepSeek v4 requer aproximadamente 2% do tamanho do cache. Isso torna muito mais fácil a implantação para manipulação de contextos muito grandes.
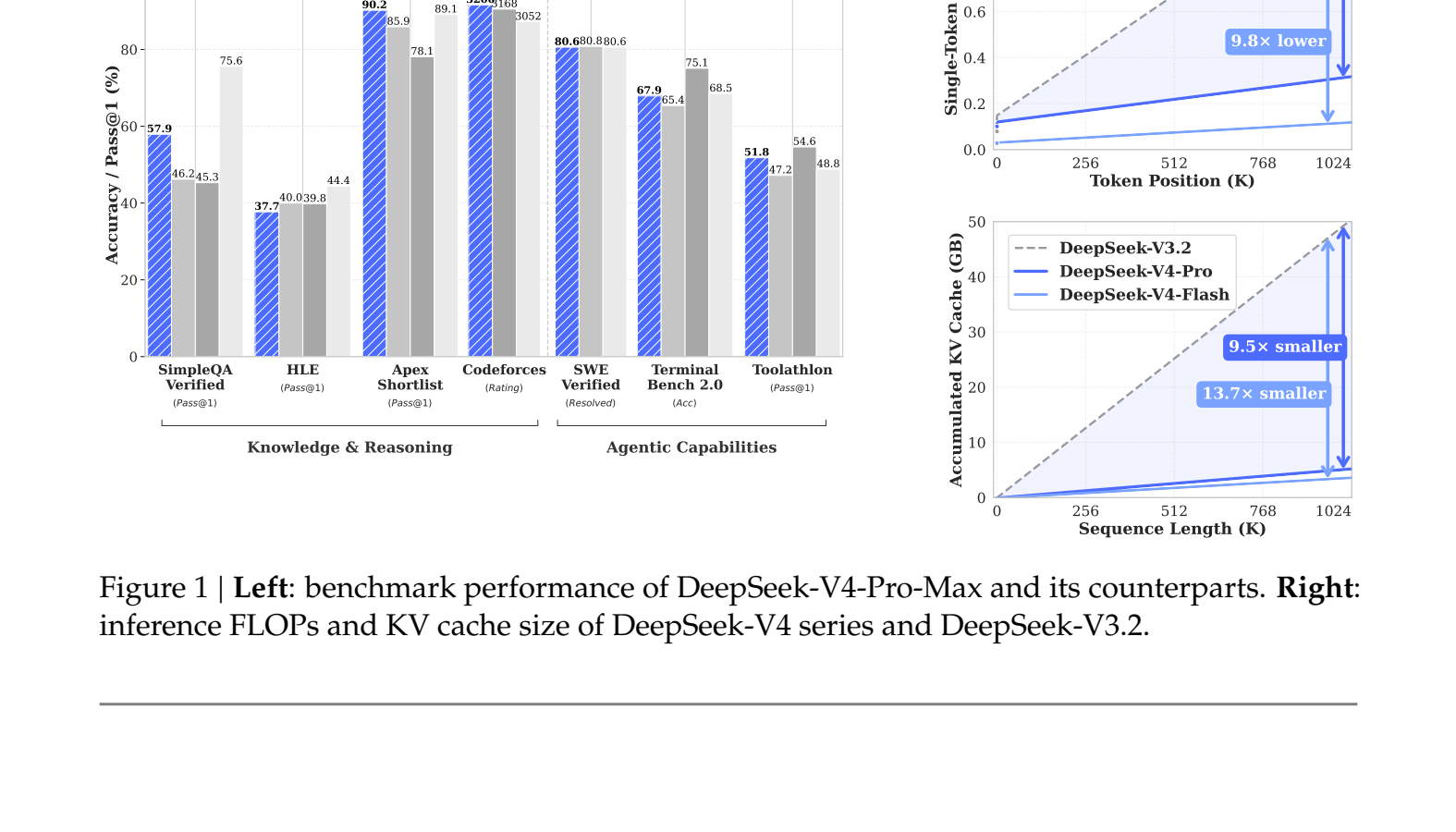
Figura 1: comparação de benchmark (esquerda), FLOPs por token e cache KV acumulado em relação ao comprimento da sequência (direita).
Atenção híbrida: CSA e HCA
O ganho de eficiência vem da divisão da atenção em dois mecanismos e da intercalação deles em camadas.
Atenção esparsa comprimida (CSA) compacta entradas KV em 4x ao longo da dimensão da sequência usando pooling controlado por softmax com uma tendência posicional aprendida. Um indexador relâmpago (FP4, produto de pontos múltiplos com pontuação ReLU) escolhe os k principais blocos compactados por consulta. Ele herda a ideia de seleção esparsa do DeepSeek Sparse Attention na V3.2, mas a executa em blocos que já são 4x mais curtos que a sequência original. O espaço de pesquisa do indexador diminui com ele.
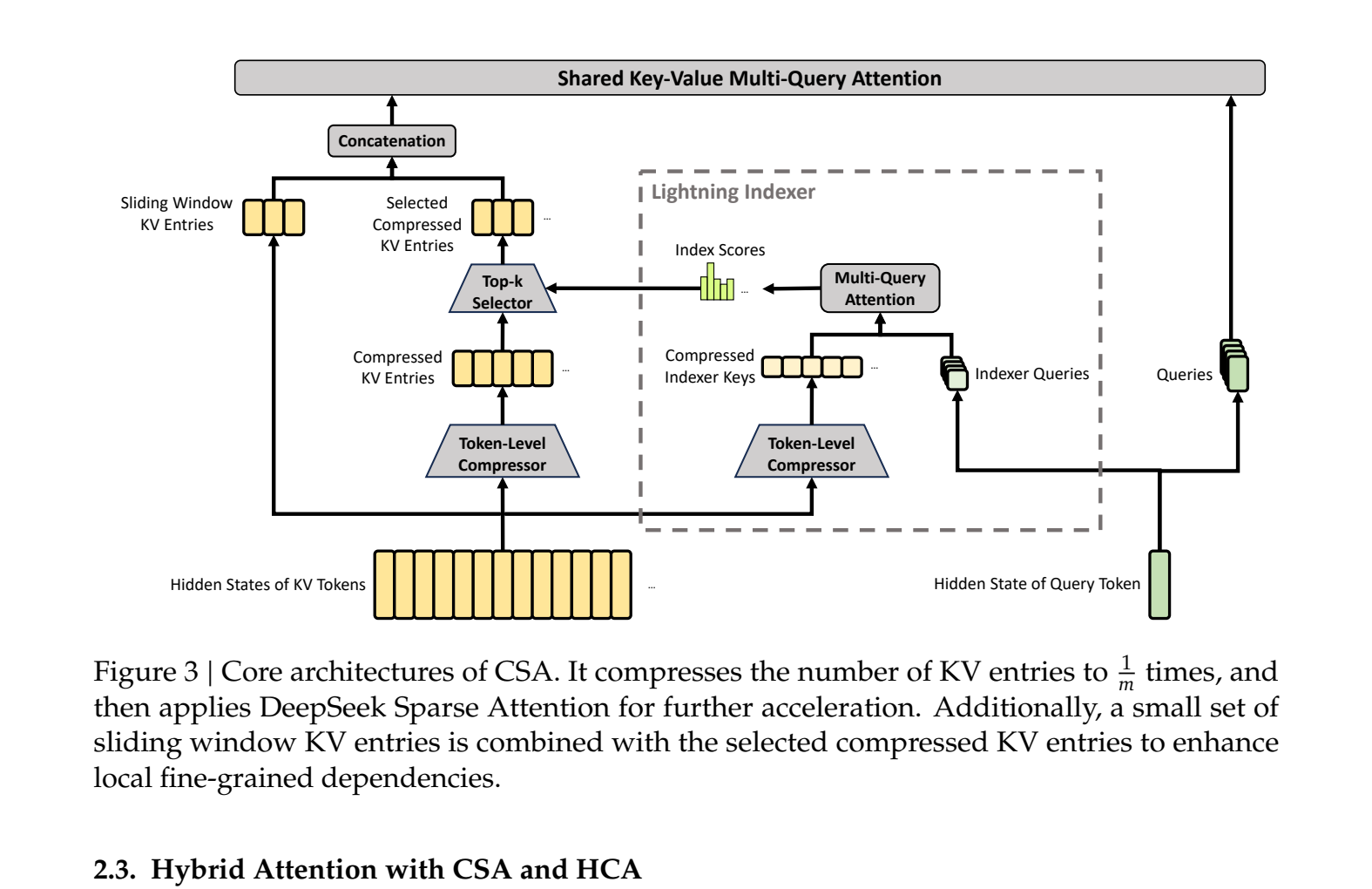
Figura 3: CSA. O compressor colapsa a cada 4 tokens em uma entrada KV compactada. O indexador relâmpago escolhe os k principais blocos compactados por consulta. Uma ramificação de janela deslizante lida com os tokens descompactados mais recentes.
Atenção Fortemente Comprimida (HCA) compacta as entradas KV em 128x e elimina a seleção esparsa. Cada consulta atende densamente a cada bloco compactado. A sequência compactada é curta o suficiente para que a atenção densa seja barata.
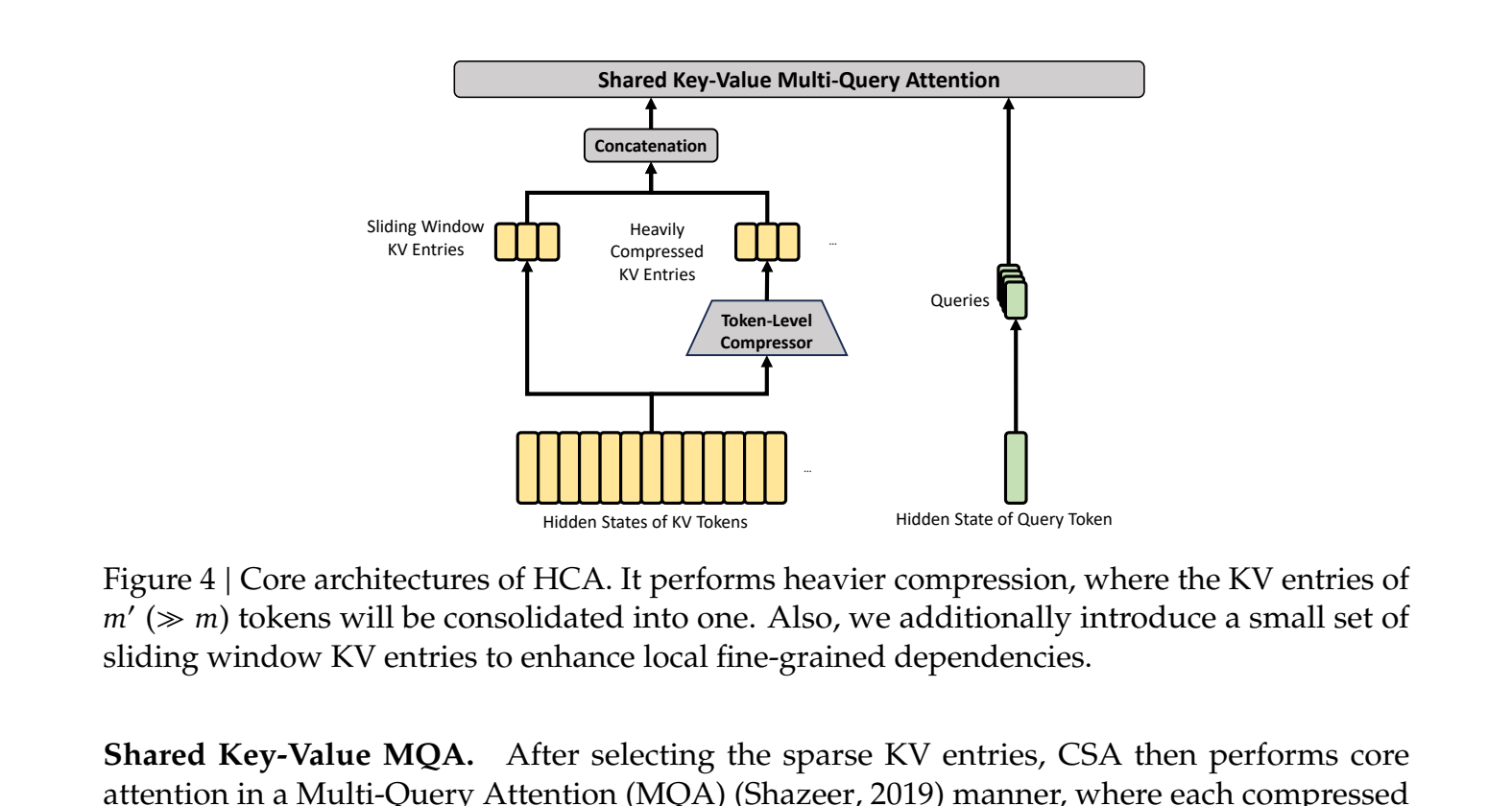
Figura 4: ACS. Um compressor mais pesado (128x vs. 4x) seguido de atenção densa sobre o fluxo comprimido, com a mesma ramificação de janela deslizante para atualidade.
As camadas alternam entre CSA e HCA. Diferentes camadas carregam diferentes padrões de atenção, e forçar um mecanismo em todas elas desperdiça capacidade. Na pilha de 61 camadas do V4-Pro, as camadas 0–1 são HCA, as camadas 2–60 alternam CSA e HCA, e o bloco MTP no final executa apenas janela deslizante.
Ambos os caminhos utilizam armazenamento FP8 para a maioria das entradas KV e BF16 apenas para as dimensões RoPE. O indexador relâmpago dentro do CSA é executado no FP4. Essas opções de armazenamento são combinadas com as taxas de compactação para produzir o valor de cache de 2% KV.
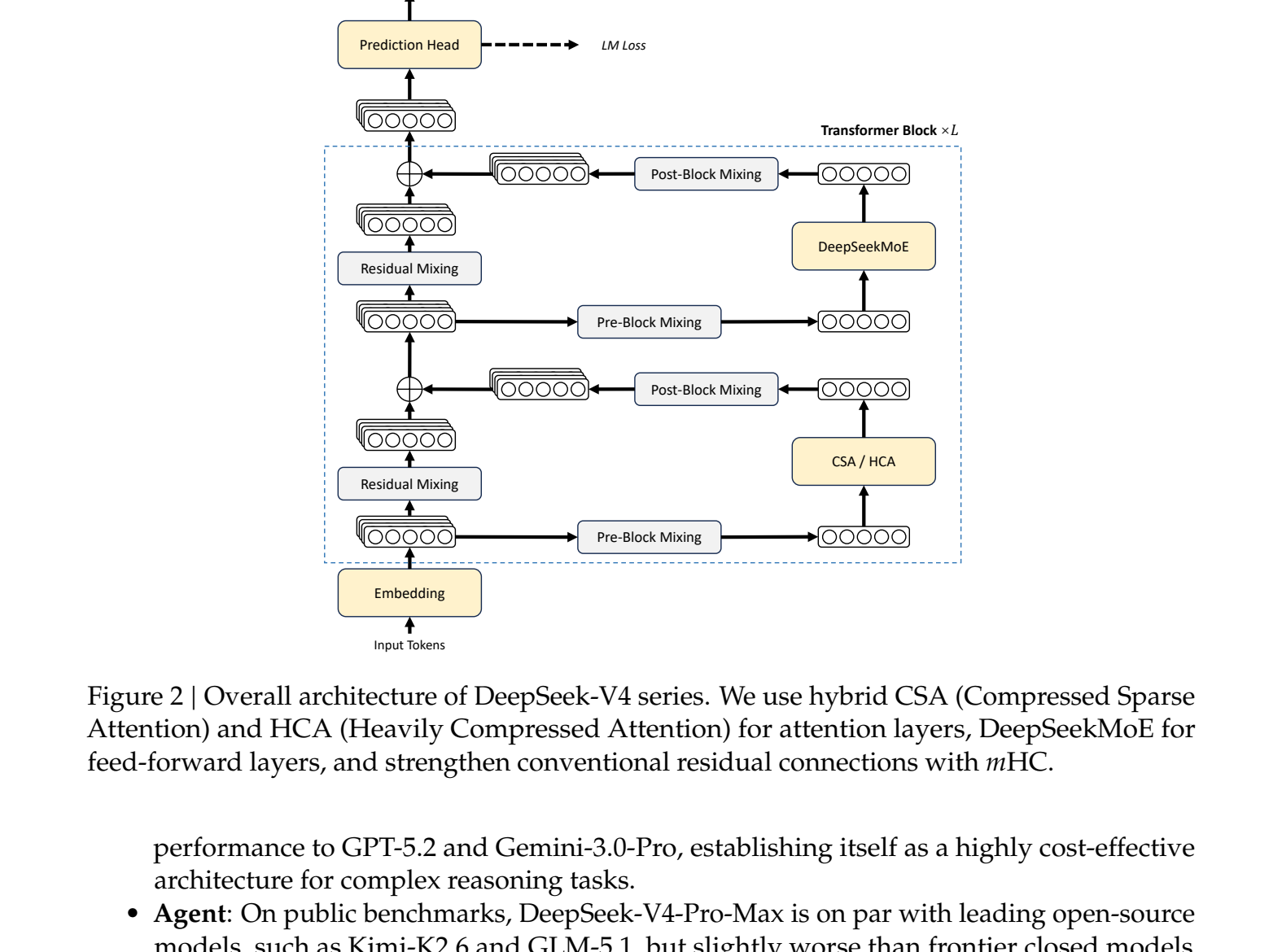
Figura 2: arquitetura geral. As camadas de atenção alternam entre CSA e HCA. Camadas feedforward usam DeepSeekMoE. As conexões residuais são substituídas por hiperconexões com restrições múltiplas (mHC).
O que muda para os agentes
A atenção eficiente em contextos longos é necessária para os fluxos de trabalho dos agentes, mas não é suficiente. O artigo descreve três opções de pós-treinamento e infraestrutura que visam diretamente os casos de uso do agente.
Pensamento intercalado em chamadas de ferramenta
A V3.2 manteve os rastros de raciocínio nas rodadas de resultados da ferramenta, mas os descartou sempre que uma nova mensagem do usuário chegava. Para um agente que cuida de um turno de usuário único, isso era bom. Para fluxos de trabalho de agente multiturno, onde o usuário envia um acompanhamento após o agente já ter encadeado diversas chamadas de ferramenta, o modelo perdeu o raciocínio acumulado e teve que reconstruir o estado.
A V4 preserva o conteúdo do raciocínio além dos limites da mensagem do usuário quando a conversa contém chamadas de ferramenta. O modelo retém o histórico completo de raciocínio em todas as rodadas, inclusive nos turnos do usuário. Isso permite uma cadeia de pensamento coerente e cumulativa sobre as tarefas do agente no longo horizonte. Para uso conversacional sem ferramentas, o comportamento antigo é preservado: o raciocínio é liberado a cada turno para manter o contexto conciso.
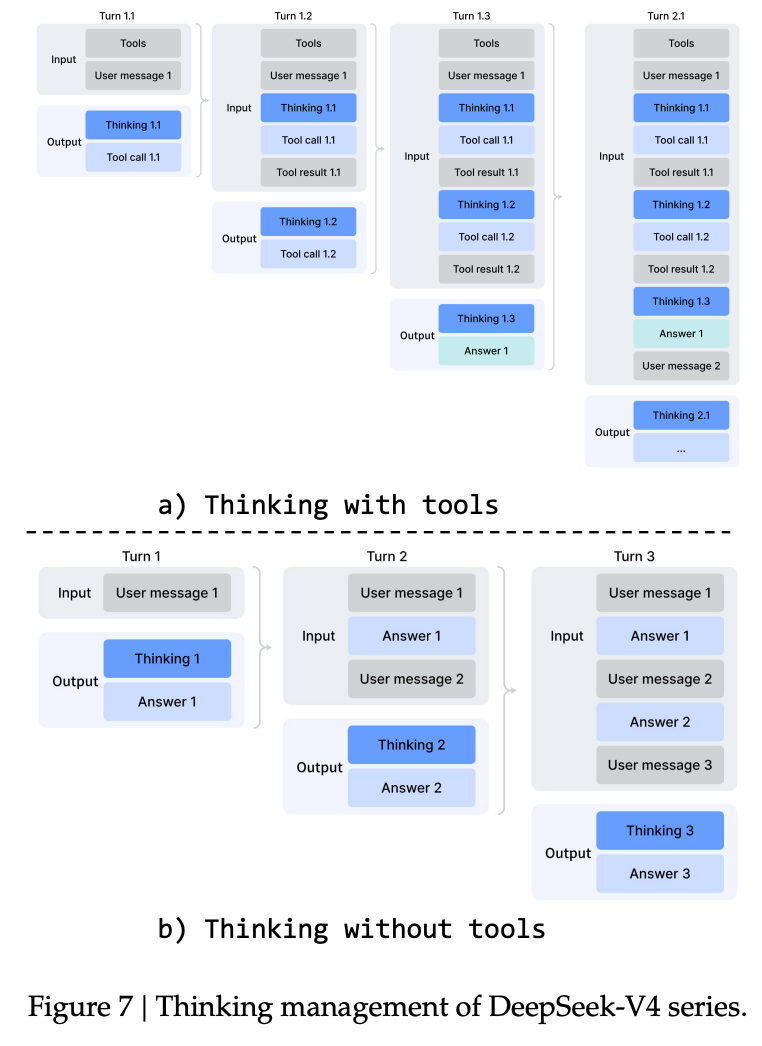
Figura 7: pensar com ferramentas (topo) preserva o raciocínio em todos os turnos. Pensar sem ferramentas (parte inferior) descarta o raciocínio a cada nova mensagem do usuário.
Esquema de chamada de ferramenta com tokens dedicados
V4 introduz um |DSML| token especial e um formato de chamada de ferramenta baseado em XML. O formato XML reduz falhas de escape em comparação com chamadas de ferramenta JSON em string, um modo de falha comum quando os modelos emitem conteúdo citado aninhado.
O esquema separa parâmetros de string (passados como estão com string="true") a partir de parâmetros estruturados (passados como JSON com string="false"). Isso remove uma classe de erros de análise em torno de números e booleanos que os formatos de chamada de ferramenta JSON atingem rotineiramente.
DSec: um sandbox criado para implementações de RL
O comportamento do agente foi treinado com RL em ambientes reais de ferramentas. O artigo descreve a infraestrutura de sandbox construída para esse fim. DeepSeek Elastic Compute (DSec) é uma plataforma Rust que expõe quatro substratos de execução por trás de um SDK Python: chamadas de função, contêineres, microVMs (Firecracker) e VMs completas (QEMU). Um único cluster executa centenas de milhares de sandboxes simultâneos.
Três recursos DSec são importantes para o treinamento do agente: carregamento rápido de imagens por meio de armazenamento 3FS em camadas (para que as implementações de RL não esperem pela inicialização do contêiner), repetição de trajetória segura com preempção (para que as etapas de treinamento interrompidas sejam retomadas sem reexecutar chamadas de ferramenta) e uma API uniforme entre substratos (para que o treinamento aproveite chamadas de função de destino ou VMs completas sem reescrever). Estas decisões de infraestrutura sustentam as pontuações de benchmark do agente.
Resultados de benchmark do agente
Os números de conhecimento e raciocínio são competitivos, mas não líderes. Os números dos agentes são onde o V4-Pro-Max se separa do campo.
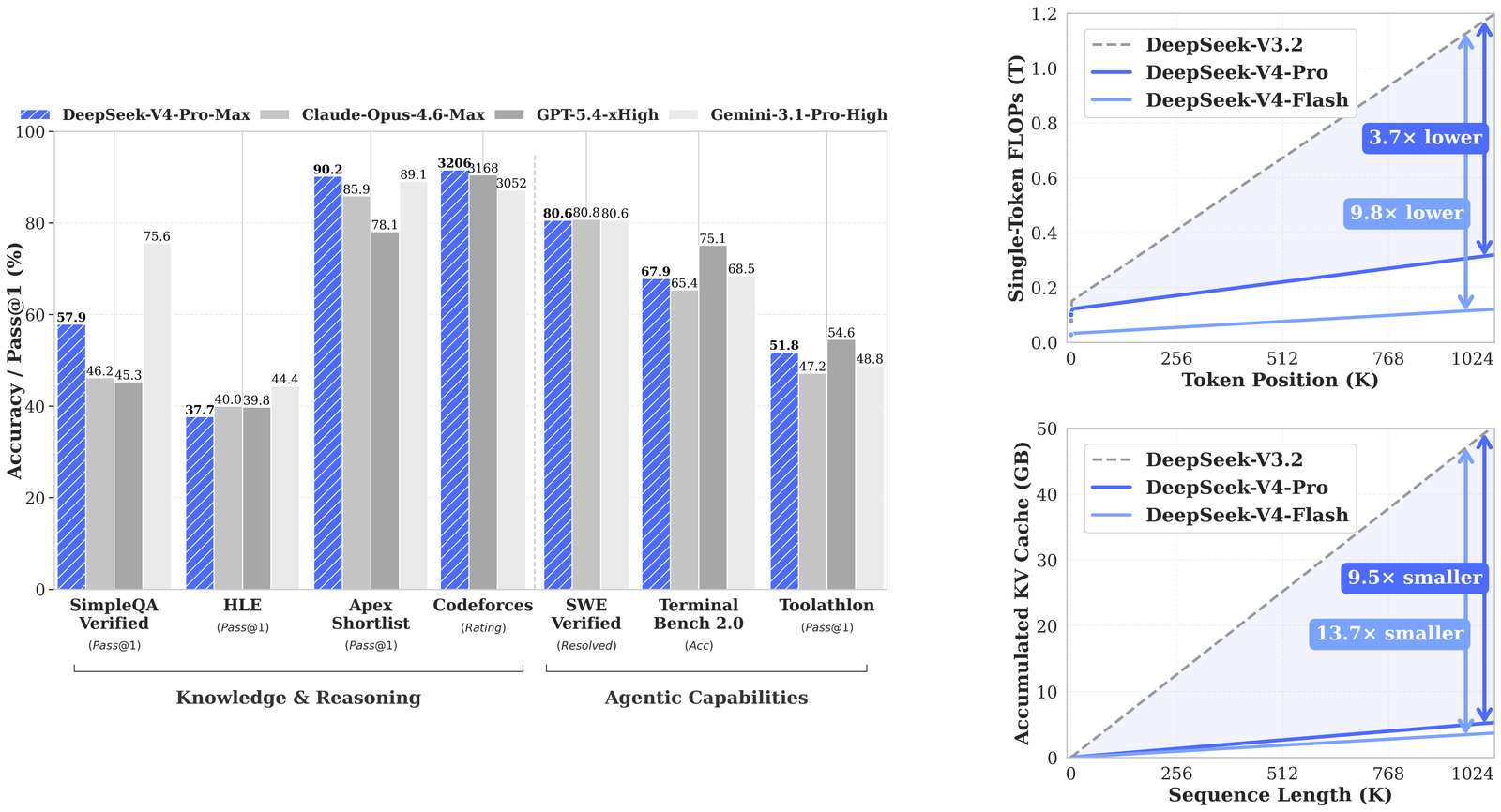
Números específicos da seção de agentes da Tabela 6:
- Terminal Bench 2.0: V4-Pro-Max pontua 67,9, à frente de GLM-5.1 (63,5) e K2.6 (66,7), atrás de GPT-5.4-xHigh (75,1) e Gemini-3.1-Pro (68,5).
- SWE verificado: 80,6 resolvido, dentro de um ponto de Opus-4.6-Max (80,8) e Gemini-3.1-Pro (80,6).
- MCPAtlas Público: 73,6, perdendo apenas para Opus-4.6-Max (73,8).
- Toolathlon: 51,8, à frente de K2.6 (50,0), GLM-5.1 (40,7) e Gemini-3.1-Pro (48,8).
No benchmark interno de codificação de P&D do artigo, 30 tarefas selecionadas em PyTorch, CUDA, Rust e C++, V4-Pro-Max atinge taxa de aprovação de 67%, contra 47% para Sonnet 4.5 e 70% para Opus 4.5. Em uma pesquisa com 85 desenvolvedores do DeepSeek que usam o V4-Pro como driver diário, 52% disseram que ele estava pronto para substituir seu modelo de codificação primário atual e 39% preferiram sim.
Os números de recuperação de contexto longo estão na Figura 9. A precisão da agulha MRCR de 8 permanece acima de 0,82 até 256 mil tokens e se mantém em 0,59 a 1 milhão.
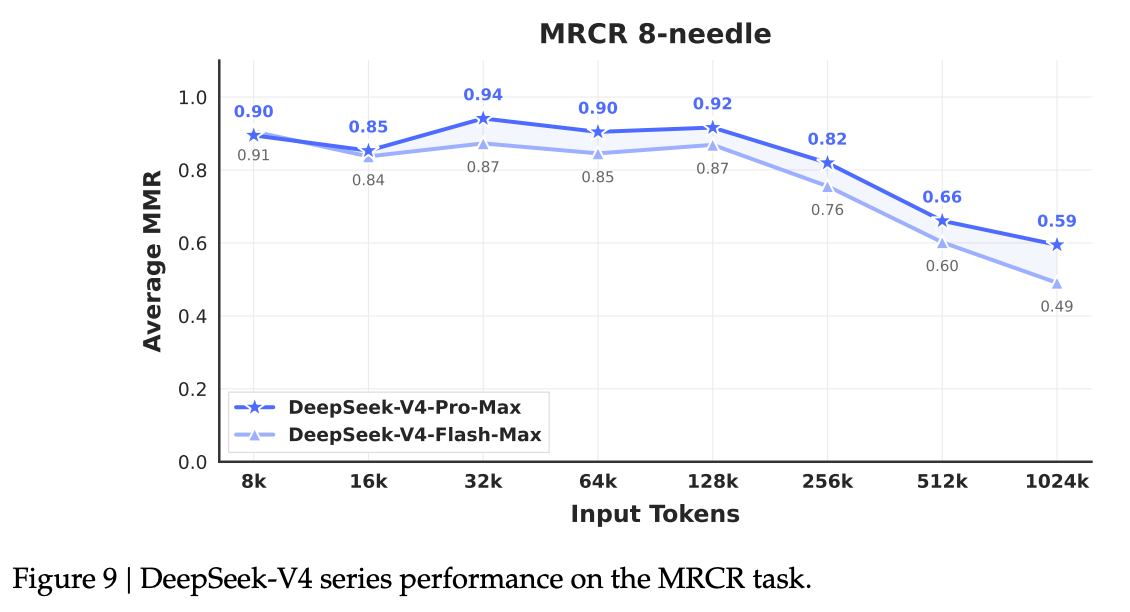
Figura 9: Recuperação de 8 agulhas MRCR. V4-Pro-Max permanece acima de 0,82 até 256K e se mantém em 0,59 em 1M.
Usando os modelos
Quatro pontos de verificação estão no Hub. Os modelos instrutivos usam FP4 para pesos especializados do MoE e FP8 para todo o resto. Os modelos básicos são totalmente FP8.
Ambos os modelos de instrução suportam três modos de raciocínio: Não pensar (rápido, sem cadeia de pensamento), Pensar alto (raciocínio explícito em
blocos) e Think Max (esforço máximo de raciocínio com um prompt de sistema dedicado). Think Max requer uma janela de contexto de pelo menos 384 mil tokens. Os parâmetros de amostragem recomendados em todos os modos são temperature=1.0, top_p=1.0.
Os números V4-Pro no SWE Verified, MCPAtlas e o benchmark interno de P&D o colocam em paridade com modelos fechados de fronteira nas tarefas dos agentes. A questão em aberto é como os recursos de ferramentas da comunidade se adaptam ao |DSML| esquema e se o pensamento intercalado ganha transferência para estruturas de agentes fora do domínio.
Os números nesta postagem do blog são do relatório técnico em DeepSeek_V4.pdf.
💡 Insight NeuralNet: A adoção de IA deve ser estratégica, não apenas tecnológica. Priorize ferramentas com transparência, ética e alinhamento aos objetivos do seu negócio ou carreira.
📈 Tendências e Aplicações em Destaque
| Área de IA | Aplicação Prática | Maturidade no Brasil | Potencial |
|---|---|---|---|
| IA Generativa | Criação de conteúdo, código e design | 🟡 Em expansão | ⭐⭐⭐⭐⭐ |
| Machine Learning | Análise preditiva, automação de processos | 🟢 Consolidado | ⭐⭐⭐⭐ |
| IA Ética & Governança | Compliance, auditoria de algoritmos | 🔵 Emergente | ⭐⭐⭐⭐⭐ |
📚 Leia Também no NeuralNet:
Fontes: huggingface.co | arXiv | MIT Technology Review | Dados de mercado
Publicado em: 2026-04-24 00:00:00 | Traduzido e adaptado por: NeuralNet
Link original: Ver matéria completa na fonte
Tags: Inteligência Artificial, Machine Learning, IA Generativa, Automação, Ética em IA, Tecnologia, Inovação, Brasil, LLM, Deep Learning
Share this content: